Database Keys: The Complete Guide (Surrogate, Natural, Composite & More)
Natural key, surrogate key, composite key.
What do these terms mean? And why should you know what they are?
In this article, you’ll learn what these terms are, so you can communicate better with other developers and understand other online tutorials that use these terms.

What is a Key?
When we are working with databases, we store data in tables. Tables are a collection of the same type of record. A table has columns.
A “key” is a field in a table that is used in the identification of that record.
That seems pretty broad, but that’s because there are different types of keys.
I mentioned a few of them earlier, so we’ll explain each of them and what they are used for.
Why should you know about the different types of keys?
First, it helps you communicate with others better. In software development, there are a range of terms that we have invented or implemented to describe how something works. This makes it easier to communicate. Developers use the word “inheritance” instead of “make this object a sub-type of that object”. The same can be said for the different types of keys.
Secondly, it will help you consider new ways of designing your database, especially when deciding on what your primary key would be. This will make more sense as we look at the different types of keys.
What Are The Different Types of Keys?
In relational databases, there are several different types of keys:
- Primary key
- Natural key
- Surrogate key
- Composite key
- Alternate key
- Unique key
- Foreign key
We’ll look at each of them in this article, explain what they are, and show some examples.
So let’s start with the main one - a primary key.
What is a Primary Key?
A primary key is one or more columns in a table that are used to uniquely identify the row.
When you're working with a relational database, you have multiple tables and you need to link them to each other. There needs to be a way to identify records, even if data changes. The way to do this is using a primary key.

It's kind of like how when you speak to your bank, insurance company, or government department, they ask for an ID:
- Banks ask for a customer or account number.
- Insurance companies ask for your member number.
- Government departments ask for your Tax File Number (here in Australia) or perhaps your Social Security Number in the US.
That way, it doesn't matter if you change your name or address, there is always an identifier that can be used to find your information.
Let’s look at an example - a bank account.
Say you’ve gone to a bank, filled out some forms, and created an account with them. You have a customer record with them, that might look like this:
- Customer Number: 2458760357
- First Name: Ben
- Last Name: Brumm
- Address: 123 Main St, Melbourne, VIC, Australia 3000
- Phone: 0412 345 678
- ...
When you call or visit the bank, you are often asked to provide your customer number. This is so the bank can easily find the right record in the system. The customer number is the primary key as it can be used to identify you and only you.
If you use your name, it may not be unique. There could be another Ben Brumm with the same bank.
Also, if you decide to change your name, or your address, you can change that without you or the bank having issues identifying you. You’ll always be customer 2458760357 to the bank, no matter what your address is.
This is what a primary key is. The primary key definition is a column or set of columns used to uniquely identify a row.
Primary keys can be created on the database when creating a table, or afterwards. You can read more in this guide to constraints.
What are the Primary Key Requirements?
A primary key has several requirements.
First, the data in the columns must be unique. If there is a second record that is added with the same values for the primary key as an existing record, the new record won't be inserted. You'll get an error saying the primary key says a record already exists.
Also, the columns in the primary key cannot contain NULL values. You must specify a value.
Finally, a table can have only one primary key. You can't create a second primary key on a different set of columns after you've created your primary key.
Natural Key
What is a Natural Key?
A natural key is an attribute that exists in the real world or is used by the business. It can be used to uniquely identify the row.

Not all types of keys use attributes that are used in the real world, but those that do are called natural keys.
An example of a natural key is a Social Security Number (for US citizens). It’s usually a unique number that applies to a person, and has a use for tax purposes. In Australia, we have a Tax File Number (TFN) which has a similar purpose. It’s a way to uniquely identify a record, and actually has a meaning in the world outside the database.
Another example of a natural key could be a country name. These are unique, and have a meaning outside of a database used to store them.
Advantages of a Natural Key
When designing your database, you’ll need to choose a primary key for each of your tables. One option you have is to choose a natural key.
There are several advantages of using a natural key as a primary key:
- It already exists, meaning you don’t need to create a new column in your table.
- It simplifies the quality of your data as it ensures only one row can exist for this value
Disadvantages of a Natural Key
If you want to use a natural key as your primary key, there is one main disadvantage:
Risk of change to business rules.
Because it is tied to or related to a business concept, then there can be issues if the business rules change. For example, if the number of digits in a Social Security Number increases, or if your natural key changes from numbers to numbers and characters, then you’ll need to adjust your table accordingly.
Or, if the rules change and this value is no longer unique, it can cause issues in your table. It can also cause issues if this number can be reused or assigned to another record (e.g. a different person has the same Social Security Number).
So, while it may be easier to use a natural key as it already exists, the risk of change to business rules is something to consider.
Do I recommend using a natural key? Well, I have my recommendation later in this article, so keep reading.
Surely there are other ways to create a primary key? Yes, there are. Let’s look at some of the other types of keys.
Surrogate Key
What is a Surrogate Key?
The word surrogate means substitute. A surrogate key is an attribute that is invented or made up for the sole purpose of being used as the primary key. It has no value to the business or the real world.

An example of a surrogate key is an “address ID” for a table of addresses. Outside of the system, an address ID has no value to anyone. But for the database, it’s used to uniquely identify the record.
Surrogate keys are often used when there is no other way to identify a record - when there is no natural key. They are often an integer value, starting at 1 and incrementing for each new record.
A lot of examples online use this concept for a primary key.
Advantages of a Surrogate Key
There are several advantages using a surrogate key for your primary key:
- It has no business or real world value, which means you have control over the format and usage of the value. No matter what happens to the other data in the record (e.g. change in formats or types), this key won’t change.
- It's easy to define. There's no need to work out which of the existing attributes can make a key, as you can use a new column for the identifier.
Disadvantages of a Surrogate Key
There are a few disadvantages of using a surrogate key as your primary key:
- It’s another extra column in your table, which increases storage space. However, storage is cheap so this may not be an issue.
- You can’t look at the key and determine anything about the record, unlike a Social Security Number or a Country Name.
I’ll share my recommendation for primary keys later in this post after we’ve looked at different types of keys.
Composite Key
What is a Composite Key?
A composite key is a primary key, or unique identifier, that is made up or more than one attribute.

The examples we’ve looked at so far mention a single attribute. However, I believe most databases let you use more than one column as a primary key. If you do, this is called a composite key.
An example of this would be identifying an address by combining the street number, street name, city, and postal code. Depending on your database, this may uniquely identify an address. If so, it could be used as a composite key.
These fields could not be used individually to identify an address. Street numbers can be repeated, and so can street names. However, the combination of all of these fields would be unique.
Another example could be the combination of first name, last name, and date of birth. It seems pretty unique, but it may not be (as mentioned below in the disadvantages).
Advantages of a Composite Key
The advantages of using a composite key as a primary key are:
- The attributes already exist, so you don’t need to create any new attributes or columns on your table like you do with the surrogate key. This simplifies the table and reduces storage.
- The combination of the attributes ensures the record is unique, like the natural key
- It allows you to use business values to identify a record if a single value does not uniquely identify a record. If a natural key doesn’t work, you can use a composite key.
Disadvantages of a Composite Key
The disadvantages of using a composite key as a primary key are:
- Risk of change to the business rules. Like a natural key, if any of the business rules change (type of field, format of data) then this will need to be updated. Also, the data may no longer uniquely identify a row so you may need to expand your composite key.
- All fields are needed in related tables. When you want to refer to this record from another table, you’ll need to store all of the fields in the composite key in another table.
Natural Key vs Surrogate Key vs Composite Key
The natural and surrogate key seem like opposites to each other, and composite key is a little different. How do they compare?
| Criteria | Natural | Surrogate | Composite |
|---|---|---|---|
| Definition | An attribute that is relevant to the real world | An attribute that has no value to the real world | More than one attribute that is relevant to the real world |
| Example | Social Security Number | Customer ID | First Name, Last Name, Date of Birth |
| Attribute already exists? | Yes | No | Yes |
| Database controls the format? | No | Yes | No |
| Impact if business rules change? | Medium-High | Minimal | High |
Candidate Key
You might have heard the term “candidate key” before as well. What is it?

A candidate key is any field in the table that could be used as a primary key because it is unique. It can be a natural key, surrogate key, or a composite key.
Using our earlier examples, these would be candidate keys for a “customer” table:
- Social Security Number
- Customer ID
- First Name, Last Name, Date of Birth
These keys are all candidate keys, as they are an option or candidate to be the primary key. They don’t contain any redundant attributes - we don’t specify “Social Security Number and First Name” as a candidate key, because Social Security Number is a key by itself.
Unlike the previous keys we looked at (Natural, Surrogate, Composite), a candidate key is a name for existing types of keys, and not a new type of key.
Alternate Key
An alternate key is any of the candidate keys that are not the primary key.

They are an option or alternate to the primary key. This can also be called a unique key.
For example, using the candidate keys above:
- Social Security Number
- Customer ID
- First Name, Last Name, Date of Birth
If the Social Security Number was chosen as the primary key, then Customer ID and “First Name, Last Name, Date of Birth” would be alternate keys.
Unlike the previous keys we looked at (Natural, Surrogate, Composite), an alternate key is a name for existing types of keys, and not a new type of key.
Unique Key
A unique key is an attribute in the table which is unique. It can be used to identify a row, but may not be the primary key. This can also be called an alternate key.
[caption id="attachment_8841" align="alignright" width="285"]

This is because a table can have only one primary key. But there may be more than one unique value in the table.
For example, consider a country table that has these fields:
- Country ID
- ISO Code
- Country Name
The country ID may be the primary key. The ISO code may also be a unique value, and would be a unique key. However, as we already have a primary key, we can’t make this column the primary key as well. It can be a unique key.
What’s the Difference between a Primary Key and a Unique Key?
A primary key and a unique key are similar, but there are some differences.
| Characteristic | Primary Key | Unique Key |
|---|---|---|
| How many can a table have? | One | Zero, one, or many |
| How are indexes created? | Created automatically | Created automatically |
| Can have more than one column | Yes | Yes |
| Can have duplicate values | No | No |
| Can have NULL values | No | Yes |
The decision on whether to create a primary key or a unique key depends on what your aim is.
If it's the key used to uniquely identify the record and to be linked to other tables using foreign keys, create a primary key. If it's a constraint to ensure a value is unique, but not linked to other tables, use a unique index or unique constraint.
Foreign Key
A foreign key is a column or set of columns in a table that refers to a primary key in another table.

They are used to specify that this record in this table is related to that record in that table.
Using the earlier customer and bank account example, you are a customer at a bank. You may have several accounts with that bank. These account details would be records in an account table.
Why would you need a foreign key?
Using the example above, an account belongs to a customer. To be able to see which customer the account belongs to, there needs to be information in the account record to hold this.
We could store the customer name, but what if the customer name changes? We would have to update every record in the account table. What if we miss one?
Also, how do we know it's unique? Are we sure that “John” and “John Smith” are the same or are they different?
If we use a foreign key, then it refers to a specific record in another table and is accurate.
So, the foreign key definition is a column or set of columns that is used to refer to another table's primary key.
What’s the Difference between a Primary Key and a Foreign Key?
Now that we've explained the primary key definition and the foreign key definition, let's see what the differences are.
This table here highlights some of the differences between primary and foreign keys. This is focused on Oracle SQL but can apply to other SQL vendors.
| Characteristic | Primary Key | Foreign Key |
|---|---|---|
| How many can a table have? | One | One or many |
| How are indexes created? | Created automatically | Not created automatically but can (and should) be |
| Can have more than one column | Yes | Yes |
| Can have duplicate values | No | Yes |
| Can have NULL values | No | Yes |
| Uniquely identify a row in a table | Yes | Not always |
In summary:
- A table can only have one primary key, but can have many foreign keys. A table doesn't need a primary key or foreign key in Oracle.
- Indexes are automatically created on primary keys in Oracle, but not for foreign keys.
- Both primary keys and foreign keys can be created on more than one column. Oracle allows up to 32 columns.
- Primary keys cannot contain duplicate values, but foreign keys can. This is how a "one to many" relationship is represented.
- A primary key cannot contain NULL values in any columns, but foreign keys can.
- A primary key is used to uniquely identify a row. A foreign key doesn't enforce this, but it could be (if there is only one matching value)
Why Do Relational Databases Use Primary Keys and Foreign Keys?
The main reason is to create logical relationships between two tables.
Primary keys are used to identify a record in a table. Foreign keys are used to relate one record to another record in a different table.
There is extra logic built into the database management system that enforces these rules. For example, most of the time you can't delete a primary key record that has foreign keys related to it. This is to prevent "orphaned records", or records where the foreign key points to a primary key that no longer exists.
It's good database design to do this, and it's part of the normalization process.
Can a Primary Key be a Foreign Key?
The short answer is yes.
However, primary keys only allow unique values, and foreign keys allow for duplicates, so a primary key on its own would most likely not be suitable.
You can have part of the foreign key in the primary key, if required, but it's better to create separate columns for these.
Diagram of Different Keys
Here's a diagram that shows different keys and how they can relate to each other.
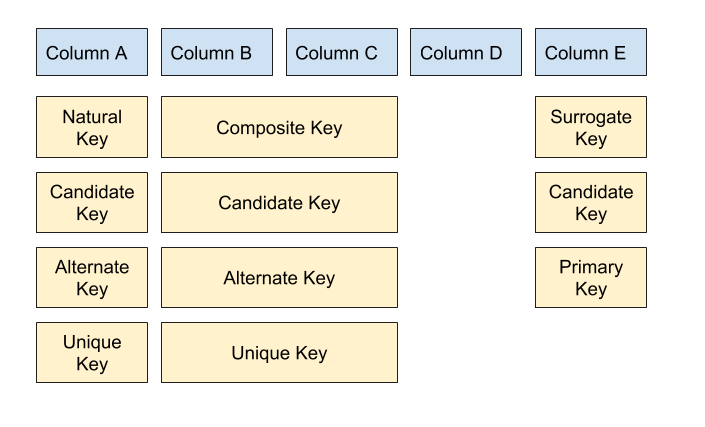
For example, Column A is a natural key. It can also be identified as a candidate key (as its one of many that could be the primary key). It wasn't chosen as the primary key, so it would be an alternate key. And because it's unique, it is a unique key.
My Recommendation
So there are three main types of keys that can be used to create a primary key:
- Natural key
- Surrogate key
- Composite key
Which one do I recommend?
I recommend using a surrogate key.
I create a new identifier column in every table, and use a built-in database feature to ensure this is unique. This is because I feel the advantages of a surrogate key outweigh the disadvantages.
In every table I’ve designed in the last few years, I’ve used a surrogate key. I’m not strictly against natural or composite keys, and would be open to using one if it made sense, but I haven’t come across a need to use one.
Summary of the Different Types of Database Keys
So, in summary, the different types of database keys are:
- Natural key: an attribute that can uniquely identify a row, and exists in the real world.
- Surrogate key: an attribute that can uniquely identify a row, and does not exist in the real world.
- Composite key: more than one attribute that when combined can uniquely identify a row.
- Primary key: the single unique identifier for the row.
- Candidate key: an attribute that could be the primary key.
- Alternate key: a candidate key that is not the primary key.
- Unique key: an attribute that can be unique on the table. Can also be called an alternate key.
- Foreign key: an attribute that is used to refer to another record in another table.
If you have any questions on these keys, let me know in the comments below!