The Ultimate Guide to Database Version Control, CI/CD, and Deployment
Using a source code repository for your application code is common practice.
Automated testing and build, commonly known as Continuous Integration and Deployment, is something a lot of organisations are working towards.
Version control and deployments often only focus on application code, with database changes following a separate process.
In this guide, I'll explain that there's a better way to handle changes to your database and how to get it under version control, tested, and deployed along with application code.

The Problems with Database Changes and Deployment
There are many problems with making changes to the database as part of software development work.
Problem 1: Manual Deployment
This is a common scenario in many organisations.
Jane, the developer, makes some code changes as part of a user story she is working on. She updates the application code, writes some unit tests, updates the automated tests, and checks in her code to the team's source control repository.
Her user story includes some changes to the database, so she has an SQL file that includes a couple of ALTER TABLE statements and some INSERT statements.
The code is tested and passes. The rest of the team get the latest version of the code, and run the SQL file to adjust their version of the database to match Jane's changes.
The team can deploy the code to a test environment for others in the team to run tests, whether they are automated or manual.
The code can then be deployed to a preprod environment by the team. One of the team members also runs the SQL script to update the table to allow for Jane's changes. They also check if there are any other changes that need to be made to preprod from anyone else's work.
So far, so good. Preprod is working as expected and the code for the user story is ready to be deployed. The team has been in control this whole time.
Now it needs to be deployed to production. The team has an automated deployment process that allows them to deploy the application code to production.
However, company policy says that changes to the database need to be implemented by a Database Administrator (let's call him Sam).
The DBA needs to:
- review the scripts used to make the changes, to ensure they won't break anything
- ensure there are rollback scripts to revert the database to the previous state if there are issues
- run the scripts in production to update the database
Because these database changes are done by Sam the DBA manually, the production deployment needs to be done outside of business hours. So, either late at night or early one morning, the DBA runs the scripts to update the database for the deployment. It also needs to be "scheduled", which means the team has to wait until a specific day and time in order to deploy.
If the scripts fail, Sam has to rollback, and try again another time after consulting with the team.
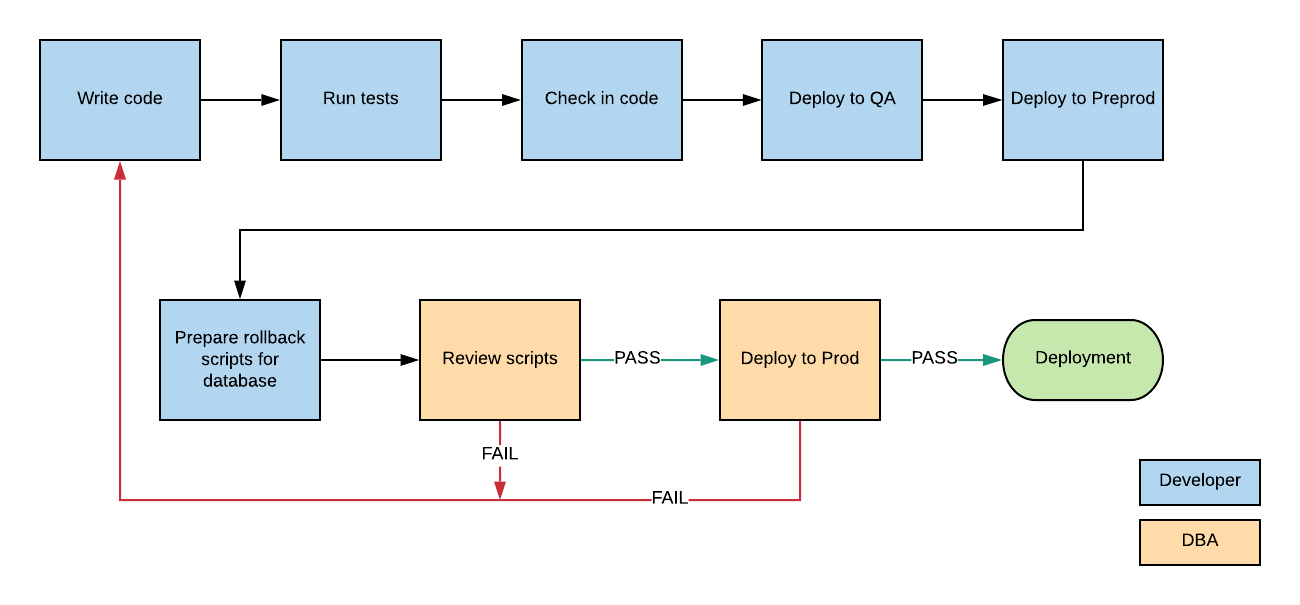
Sam the DBA isn't as familiar with the application as the development team, so he may not know how to resolve any issues.
Do you have a process like this in your organisation?
There are many issues with this kind of process:
- Deployment of the database is done by a separate person who is not familiar with the application
- Deployment is done manually which is prone to human error
- Additional time is added in to the deployment process while the team waits for the deployment date
Problem 2: Incorrect Scripts
You're on application support and you get a phone call at 3AM. There's an outage on the production system.
You roll out of bed, turn on your laptop, and start checking emails. You browse the log files that are being generated and send a few emails and Slack messages to others who are awake and looking into the issue.
After half an hour or so, you find the issue. Errors are being generated because a page is timing out. The page is timing out because the query that fetches the data is slow, and there is no index on the table.
You're pretty sure this was tested during the development stage. You're also pretty sure that Jane, the developer, added an index to this table for this reason.
You look back into the emails sent around for the latest deployment, which was only a few days ago. You find the email that contained the scripts that the team had sent to the DBA for the production deployment.
Hmm… the script that was sent did not include the CREATE INDEX statement. Jane had added that into the SQL file but it was not the same one that was sent to the DBA.
Also, the DBA did not notice that there was no index on the table. He likely didn't know one was needed, as he didn't test the application code or know the query that was using the table. He received the script and didn't know it wasn't the most up-to-date one.
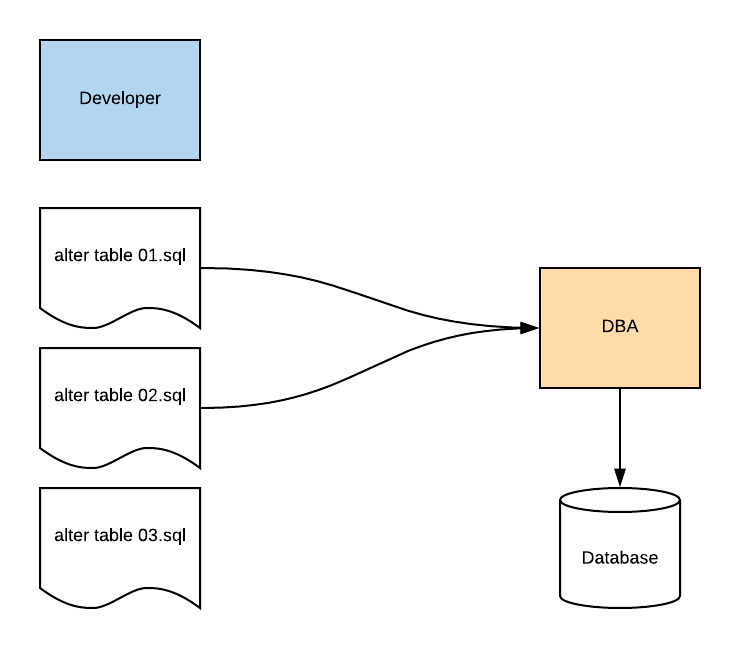
The script was run, and implemented in production, with no issues. Until three days later, when the query timed out.
After a few Slack messages and some emails, the team knows what needs to be done. You get the right script, send it to the DBA to run on production, which is successful. You re-run the impacted query and it runs in a fraction of the time. You check the page that was timing out, and it loads.
You then breathe a sigh of relief. The issue has been resolved. You email those involved to let them know, turn off your computer, and go back to sleep.
Tomorrow, you'll be tired because of this interruption, and the mood of the team may be a bit tense due to the production issue.
If only there was some way to avoid this…
This kind of situation has happened to me in the past, and I've heard of it happening to others. Using the incorrect script is a risk if the database changes are deployed manually to production by someone outside of the team and if there is no central place to store database code.
Problem 3: Multiple Copies
Jane and Bill are both developers. The development team determine it's ready to prepare the application for testing.
They can deploy the code from source control to the testing environment.
But what about the database? Jane and Bill have both been making changes to their database to cater for their application code changes.
Jane: "Which database is the current version? Yours or mine?"
Bill: "I don't know. I added a new table and a new column to the customer table. What did you change?"
Jane: "I added a new column to the customer table as well. I also added two new tables for my feature. And inserted some new rows into the customer type table - we can't forget those."
Bill: "Ok, how about you send me your changes and I can combine them?"
Jane: "But your changes sound simpler. Can you send me yours?"
Bill: "Sure. Is it easier if I export the CREATE TABLE statements or use the ALTER TABLE statements for the changes?"
Jane: "Probably the CREATE TABLE statements, just in case there are any differences we haven't seen. Actually, just send me a dump of the entire database structure and I'll compare the differences to mine."
Bill: "Sure, I'll send it to you in the next ten minutes."
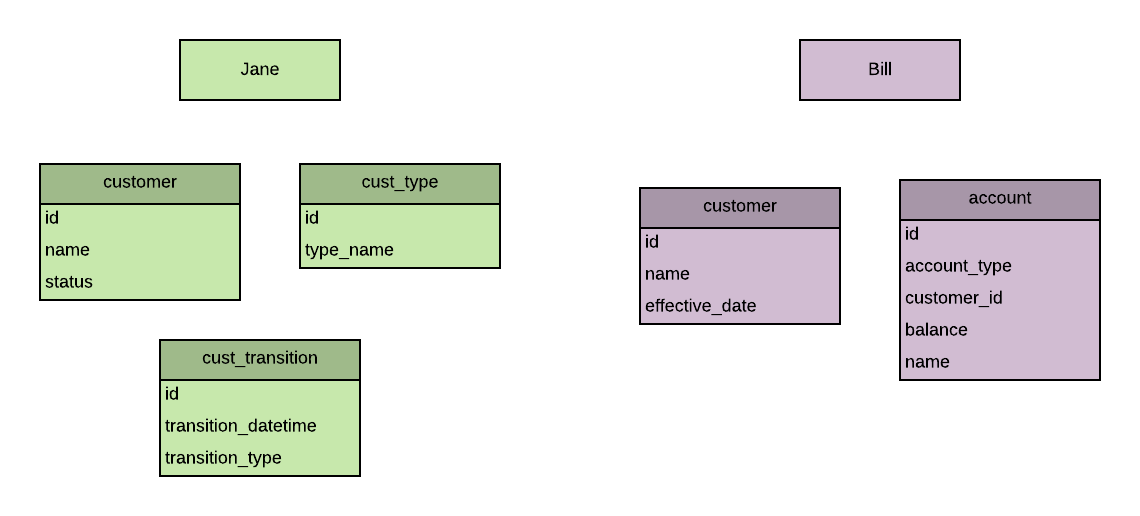
This exchange highlights a few things:
- there's no one central source of the database, like there is for application code
- it's hard to determine what has changed and if there are changes the developers have forgotten or are unaware of
- merging changes is complicated
If the correct changes are not deployed to the test environment, the tests will fail. Or, even worse, the tests won't fail and the missing changes won't get noticed until production.
Having multiple copies of the database when you're ready to deploy can cause all kinds of issues.
Summary of the Problems
So, in summary, there are a few problems with database deployments:
- Database changes are often done by DBAs outside the team, who aren't familiar with the application and may not know the database as well
- Manual deployment is prone to human error
- Manual deployment often needs to wait until the "change window" or a specific date in the future
- Incorrect scripts can be provided to others resulting in the wrong code being deployed
- Multiple copies of the database can exist on different computers, making it hard to determine the right version to use and deploy
Sounds pretty bad, right?
Fortunately there's a way around it. Database deployments can be as simple as code deployments:
- Automated
- Tested
- Contained in a single location
This guide will highlight what can be done to get to this state and avoid the problems we've mentioned.
The Solution to Manual and Complicated Database Deployments
The way to avoid the issues with manual database deployments is to automate them.
This process is called CI/CD, which stands for Continuous Integration/Continuous Delivery. It essentially means that every time a change is checked into source control, a series of tests are run, and if the tests pass, the code is deployed to another environment. This deployment could be to the test environment, preprod, and even production if the organisation wants to.
I learned about the concept of automated deployment a few years ago. I was working on a side project for a friend, and every time I wanted to deploy a change to the server, I would:
- Log in to the FTP server
- Copy all application files from my computer to the server (regardless of if they had changed or not)
- Log into the production database and run the same changes I had run on my local computer.
I thought, surely there's a better way to deploy code than to copy all my code to the server using FTP?
That's when I discovered automated testing, continuous integration and continuous delivery. I watched many YouTube videos and then read a book called Continuous Delivery.
That book blew my mind.

Being able to make a code change, check it in to source control, and have a series of tests run and automatically deploy the code, seemed incredible to me.
This is something organisations have been doing for some time.
To do this with application code is fairly simple, because the code can just replace the code that already exists in production.
However, doing this with databases is harder. The database includes two components:
- The schema (tables, views, procedures)
- The data (reference data, application generated data)
It's harder, but not impossible.
The goal, and solution to the manual deployment process for databases, is to automatically deploy database changes.
This is what's involved:
- Database code needs to be in a version control system
- Automated tests for the database need to be in place
- A deployment process needs to be able to reconstruct the database from version control
- A deployment process needs to be able to deploy the changes to another environment
We'll look at what this means and how to implement it later in this guide.
First, why do we want to do this?
Why? The Benefits of Automated Database Deployments
There are many benefits to implementing a version control/source control and automated deployment process for your database.
Single Source of Truth for the Database
It's almost unheard of these days to develop application code without using a version control system such as GitHub or Bitbucket.
But database code is a little different. It's harder, but not impossible, to get database code into version control. I've written a guide here.
The benefit of doing this is that you have a "single source of truth" for your database, which means there is one place that you know the definition of the database is correct.
You won't have any more conflicts or issues between developer's code where you try to understand who has the more current version. You just check the version control system.
It also makes it easy to deploy changes if they are stored in one place.
Easier to Share Code
If you're using a version control system, it's easier to share code between the developers. You don't need to send scripts around to the team and get them to run them to ensure their database works with your changes. Or if you fix a bug, you don't need to send the script around to everyone. Adding the code to source control makes it easier for others to get the code when they need to, all from one place.
History of Code is Available
A version control system will store a history of all code for the database, in the same way as it does for application code. This makes it easier to look back in time to find out when code was changed.
There are two methods for structuring your scripts in a version control system: state-based and migration-based. We'll get into those later in this guide. Both methods allow you to see a history when combined with a version control system.
Seeing the history of code changes is useful if you find an issue and need to resolve it, or want to know what the business need was when implementing a feature.
Reduce Time to Release Code
How long does it take to release code that you have written? Days? Weeks? Months?
Following a manual process can involve many steps, each of which will add a delay and has a potential to fail:
- Manual deployment to each environment
- Manual testing
- Approval by external team members or management
The more steps in your deployment process that are automated, the faster you can release code.
Software deployments work best when they are automated and when they are small. Small, frequent changes are preferred because there is less risk and they are easier to investigate if they fail.
If you have your database in version control and have an automated deployment process for it, you can deploy your code faster.
This means it's faster to release bug fixes, faster to release features, and faster to deliver value to users and customers.
Reduced Defects Due To Automated Tests
One of the goals of automated testing is to reduce the amount of time that developers and testers spend on testing the same features over and over. The tests are run automatically to catch any issues that have had tests written for.
Having automated tests means that there are fewer database-related defects. Tests can catch any issues in your code before they are deployed, and can test that new features don't cause issues elsewhere.
Tests are only as good as the issues you test for, so they may not catch everything, but they certainly provide a big help in finding issues that otherwise won't be found.
Reduced Time and Defects from Manual Input
There will also be fewer defects and less time spent on deployments from having no manual input.
Manual input can occur by:
- Writing scripts to make ad-hoc changes
- Sending scripts to other team members or the DBA
- Copying files to servers
Every time a manual step is performed, there is a potential for an error, due to missing a step or following it incorrectly or using the wrong file.
Each of these manual steps can be included in the automated process. This will reduce the time spent on deployments by the team, and reduce the number of defects found in the database.
Spend More Time On Useful Work
If you're spending less time on deployments and fixing issues, then you can spend more time on useful work.
So, instead of spending time on these activities:
- Sending files via email to team members
- Running deployment scripts
- Testing deployments in different environments
- Reversing or rolling back deployments to fix issues
You spend more time on these activities:
- Developing features
- Making code improvements
- Investigating new functionality and features
Improved Team Morale
If the team is spending less time doing manual deployment tasks and bug fixing, they will likely be in a better mood overall and improve their morale.
As developers, we like to automate things, and spend our time working on challenging problems. Manually running scripts over and over again is not an enjoyable task.
If the team knows their database deployments work well and are error-free, then their mood will be improved as they don't need to worry about that area of their process.
Improved Trust in Team by Organisation
The final benefit I see is that the rest of the organisation will trust the team more.
Every time there is an issue with an application, the organisation trusts the development team or IT department less. They feel the team may not be doing their job properly.
Have you ever been in a team or organisation that has had some policy that has resulted from an IT issue in the past? For example, no deployments on weeknights, which was implemented after some outage that happened a few years ago?
These kinds of policies are implemented to give the organisation a sense of stability but they also come from a lack of trust in the development team.
And then there's the biggest one of all - change freeze periods. A period of time, often over the holiday period, where no changes can be implemented in any IT system. A four to six week period of no improvements or fixes.
In my opinion, change freeze periods are a backwards policy, cause more issues than they attempt to solve, and are a relic of old deployment processes. Teams rush to get changes in before the cutoff which ends up with a big "release day" of a lot of changes, often causing more issues.
Anyway, I can talk about my dislike for these policies, but if you have an automated deployment process, you will repeatedly have issue-free deployments. If you do find an issue, you can fix it and deploy it relatively quickly. Doing this many times will improve the trust that the organisation has with your team.
The Process of Automating Your Database Deployments
So we've seen the benefits of database version control and automated database deployments.
What does the process look like?
It's essentially the same as an automated deployment process for application code, and looks something like this:
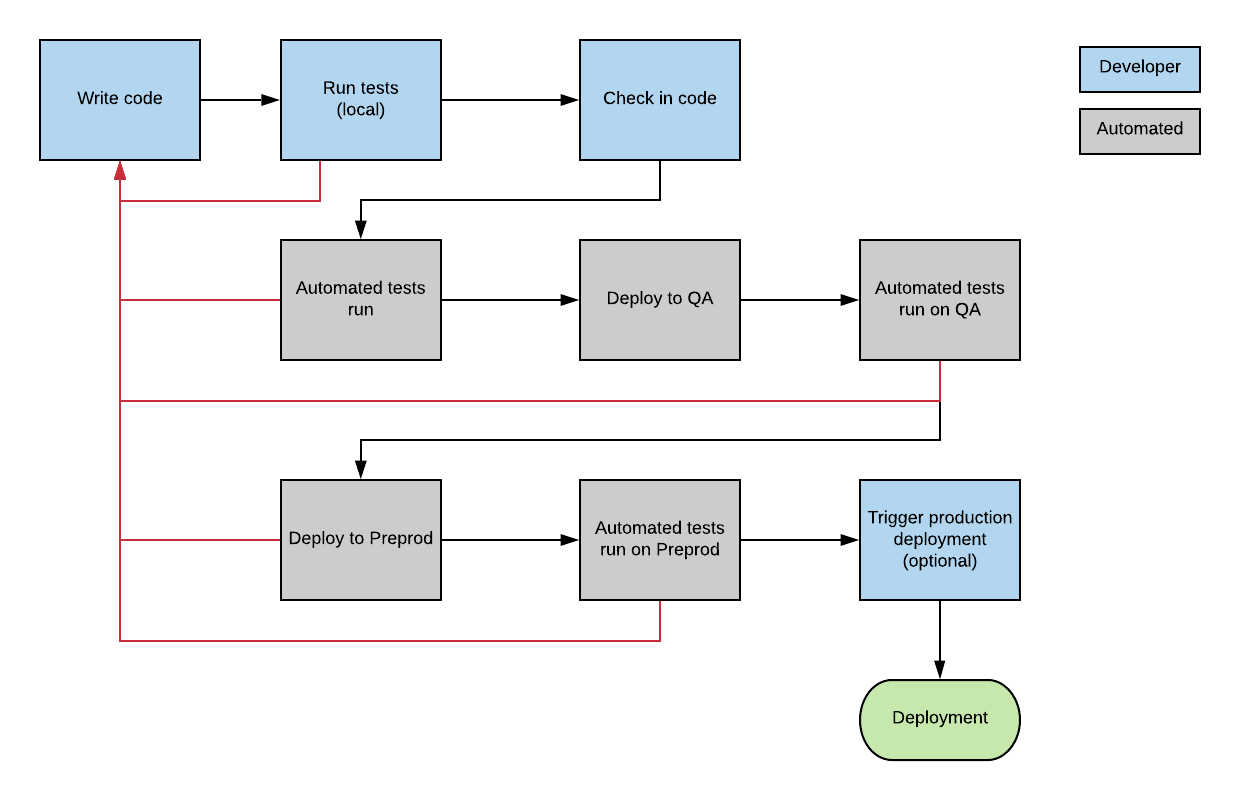
The steps in this process are:
- Developer begins work on a feature
- Developer makes changes to application code and database. This includes code changes and tests (unit tests, ideally additional tests as well)
- Developer runs automated test suite on local machine to find any issues
- Developer commits code to the source control
- Team reviews code change and merges it
- Automated test suite runs on committed code
- Code is deployed to QA environment. Database code is run which creates the database on QA and populates it with data. Perhaps test data is used or generated.
- Automated tests run on QA
- Code is deployed to another environment, such as Preprod. Database code is run again.
- Automated tests run. This may include more comprehensive tests such as integration with other systems, performance tests
- Deployment to product occurs, which can be automated, or require a manual click of a button by someone
At any point in the automated process, if a failure occurs, the process stops. The development team would then need to investigate and resolve the failure.
You might be reading that and thinking that sounds like a lot of work.
It's true, setting it up can be a lot of work. There are tools to make it easier, as it's something a lot of teams have done.
However, the effort and savings look something like this:
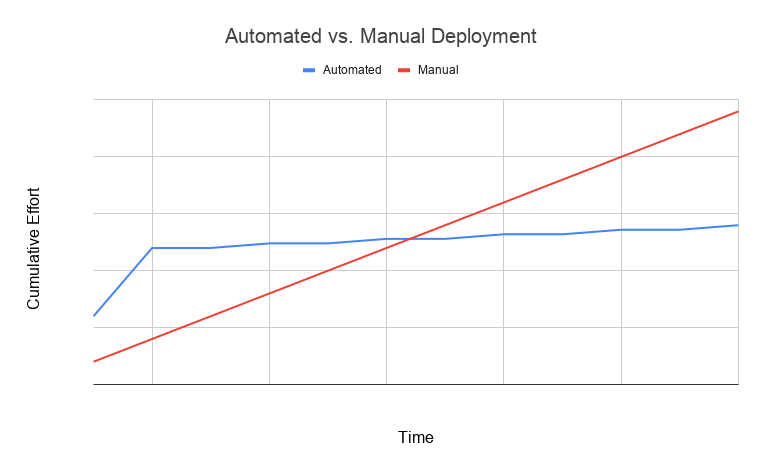
In this guide, we'll look at many parts of this process: source control, automated deployment, and automated testing.
Database Versioning and Source Control
What is database versioning?
It's the process where you share all changes made to a database in a central location (such as GitHub), so that others on your team and generate and use a common definition of the database. It includes a schema (the tables and objects) and the reference data.
When you write application code (your Java/JavaScript/CSS/HTML/C# files), you are most likely using a version control or source control system such as Github or Bitbucket. Using source control with application code makes sense as the application can be constructed from this code.
However, with databases, it's a little harder.
In simple systems, the "source of truth" is on the live system. If you want to make a change, you just log in to your favourite IDE, run a script to make a change, and it's live.
However, on anything more than just a basic system, you need something more robust.
That's where version control comes in.
Version control for a database is possible. It will help you:
- Have a single source of truth for your database code
- Build the database from scratch if needed, e.g. when a new team member joins or when you set up a new environment
- Reduce conflicts between changes by team members
Databases include two components:
- The schema: the tables, views, indexes and other objects such as stored procedures and functions
- The data: data inside the reference tables (excluding user-generated data)
All of these should be stored in version control. You need to be able to know what the latest copy of the tables are, the latest copy of the reference data, and any other database object you have. You shouldn't have to go onto the Production server to export the statements for creating an object to know what the right version is.
The artifact of the application code is just the file that contains the code. The artifact of the database, however, is not the code that creates it - it's the object itself.
How do you store the database object in version control then? You can't simply store a created table on GitHub.
The answer is, you store the scripts used to create the object.
These scripts can then be used to create objects and alter objects to get them to the required state.
An Example of Database Source Control
For example, you have a table called Customer. Here's the script you used to create it:
1CREATE TABLE customer (
2 id NUMBER,
3 first_name VARCHAR(100),
4 last_name VARCHAR(100)
5);
Once you write that script, you run it on your local database, and the table is created.
Now what? How do we get it into version control?
We add this to our source code repository. The same one that we use for the application. This is because we want to treat database code in the same way as application code.
So we would save this file as something like "create customer.sql", add it to our repository, commit it, and push it to the remote repository.
Now the script for creating this object is available in version control. Whenever anyone wants to create the customer table, rather than going to a test environment or asking someone for a script, they just run this script from the version control.
It's a simple example, but it demonstrates the concept.
Making Changes
What if you want to make changes to a database? Let's say you start work on a new user story, and you need to add a status column to the customer table.
Your customer table could then look like this:
1CREATE TABLE customer (
2 id NUMBER,
3 first_name VARCHAR(100),
4 last_name VARCHAR(100),
5 status VARCHAR(20)
6);
But, what if instead of creating the customer table from scratch, you just changed the existing table?
1ALTER TABLE customer ADD COLUMN status VARCHAR(20);
This raises an interesting question, and one that's central to how you decide to manage your database code:
Should your database code reflect the current state of the database, or should it reflect the steps taken to get to the current state of the database?
These two options are state-based version control and migration-based version-control.
Let's explain what they mean.
State Based v Migration Based
State-based and migration-based are two methods of database version control.
When you store database code that reflects the current state of the database, it's called state-based version control. You can use the code in version control to create the database, and the scripts represent what the current definitions are.
When you store database code that reflects the steps taken to get to the current state of the database, it's called migration-based version control. The scripts in the version control reflect the original script used to create the object, and all of the scripts used to get the object to where it should be.
A state-based technique for the customer table example would look like this:
customer.sql
1CREATE TABLE customer (
2 id NUMBER,
3 first_name VARCHAR(100),
4 last_name VARCHAR(100),
5 status VARCHAR(20)
6);
There would be one script file that contains the definition of the table. It would get updated whenever a change is needed to the table (such as adding a status column).
A migration-based technique for the customer table would look like this:
customer.sql
1CREATE TABLE customer (
2 id NUMBER,
3 first_name VARCHAR(100),
4 last_name VARCHAR(100)
5);
customer_add_status.sql
1ALTER TABLE customer ADD COLUMN status VARCHAR(20);
One script creates the customer table, and the next script adds the status column.
So what are the benefits of each approach?
Benefits of State-Based Development
The benefits of using a state-based development for your database are:
- Considered simpler as there is only one set of scripts (e.g. one script per object, or some other division).
- The definition of the object is in one place so anyone can open it to see what it should look like.
- The version control commit history will tell you what the changes have been, when, and who changed them.
Benefits of Migration-Based Development
- A database can be built up to a certain point, which helps in modern teams where there are multiple environments and branches
- All changes are captured in separate scripts so you know what is changing and when
- Deployments may be easier as the scripts are smaller
So which approach should you take?
This is a team decision so discuss the pros and cons with your team.
If you need help deciding, Martin Fowler has an excellent article on Evolutionary Database Design, where he includes this:
In many organisations we see a process where developers make changes to a development database using schema editing tools and ad-hoc SQL for standing data. Once they've finished their development task, then DBAs compare the development database to the production database and make the corresponding changes to the production database when promoting the software to live. But doing this at production time is tricky as the context for the changes in development is lost. The purpose of the changes needs be understood again, by a different group of people.
To avoid this we prefer to capture the change during development, and keep the change as a first class artifact that can be tested and deployed to production with the same process and control as changes to application code. We do this by representing every change to the database as a database migration script which is version controlled together with application code changes. These migration scripts include: schema changes, database code changes, reference data updates, transaction data updates, and fixes to production data problems caused by bugs.
I would recommend using migration-based deployment as the benefits seem clearer to me.
However, don't let the complexity and number of scripts turn you away from this approach. There are many tools available that make this easy for you and your team to implement.
Doesn't Running a Lot of Scripts Slow Down the Database?
One question I often see when working with deployments and databases is about the number of scripts.
What if you have hundreds of database scripts? Wouldn't it take a long time to run each of them?
Yes, it would take time, depending on the size of your database. But not as much time as you would think.
Database deployments can be the slowest part of the deployment, but there's no way to know that until you set up the deployment.
We should avoid "premature optimisation", which is where we try to optimise the performance of something before we know it's an issue. And running database scripts may not be that much of a performance issue.
However, if you do get to a point where there are a lot of scripts running and the database deployment is taking 20 minutes, for example, there are some things you can do.
You can do something called "re-baselining".
Re-Baselining Your Database Scripts
Re-baselining your database deployment scripts involves combining all of your database deployment scripts into a set of scripts that reflect the current status of the database. This can reduce the number of changes that are made to the database on the same object, which reduces deployment time.
For example, let's say over a period of a year, several changes are made to a table:
- Create the table from the original script
- Add a new column
- Add an index
- Change a data type of a column
- Add three more columns
- Remove a column
- Split the table into two tables
After all of these scripts it can be hard to tell what the table looks like.
Instead of running all of these scripts for each deployment, you can re-baseline your scripts. This means you can create a script that creates the database in its current state, instead of running all of these migrations.
The way to do this depends on the tool you use, but it goes something like this:
- Take a database dump of your most recent database. This can be from any environment, if you're using your database scripts from version control.
- Alter the scripts so they don't delete any user-generated data. This might include creating copies of the current tables in order to migrate data from
- Add this script to version control and deploy it
- Test the new database to ensure it works
- Replace your old scripts with this script
There can be quite a bit of work involved in this process, depending on your application and the size of the database. But it's one thing to consider if your database deployments are slow.
An Example Migration-Based Version Control Approach with Flyway
One popular database migration tool is called Flyway. It's open source, and I'll use it in this example. Related: How to Set Up Flyway DB
Let's say you have your database which has some tables and data in each of these tables.
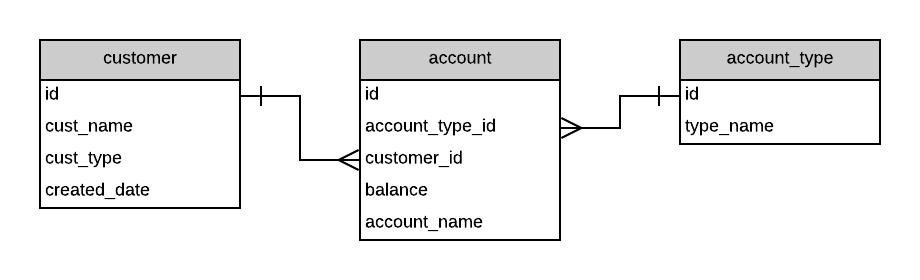
Flyway is installed and run. It looks in your database for a "schema history" table, which is a table that lists all of the changes made to the schema over time. As Flyway has just been installed, this table does not exist, so it's created.
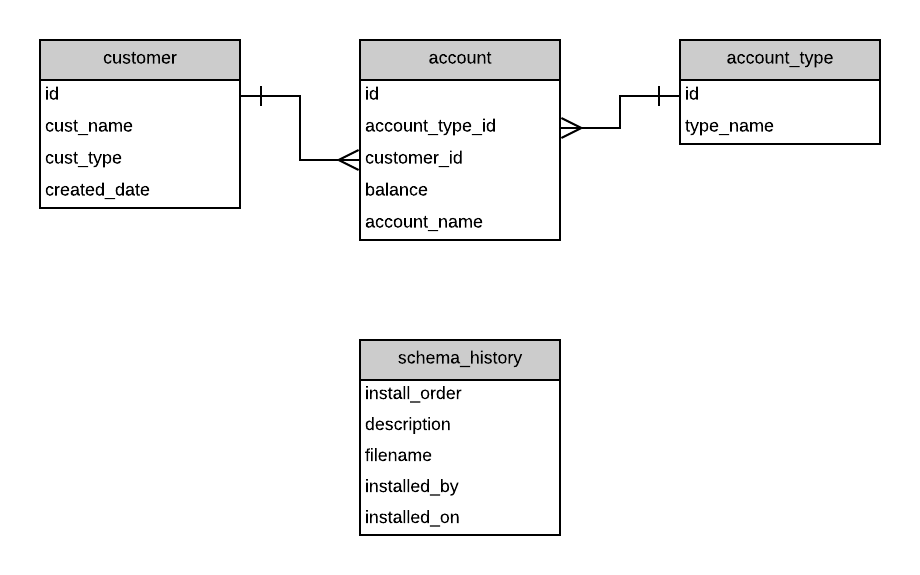
When you make a change to the database (such as adding a new table), you store the SQL script for this change in a specific place in your folder structure. It should also be given a name that includes a file number and a description (such as "001 new customer type table.sql").
Flyway will then find this file and add an entry to it in the schema version table. Other tools work in a similar way. Your version table then looks like this:
| Install Order | Description | Filename | Installed By | Installed On |
|---|---|---|---|---|
| 1 | New Customer Type Table | 001 new customer type table.sql | bbrumm | 2019-01-18 12:20 PM |
New records are added to this table whenever new scripts are created:
| Install Order | Description | Filename | Installed By | Installed On |
|---|---|---|---|---|
| 1 | New Customer Type Table | 001 new customer type table.sql | bbrumm | 2019-01-18 12:20 PM |
| 2 | Alter customer table | 002 alter cust table.sql | bbrumm | 2019-01-18 12:35 PM |
When you deploy your database and application to another environment, Flyway will check this table and compare it against the scripts folder. If there are scripts in the folder that are not in this table, then the scripts are run on the database.
For example, if your local development environment had the two records above in the version table, but the QA environment only had the first record, then the second script would get run in the QA environment.
This means you don't need to run the scripts manually. You just write the scripts and Flyway works out which scripts need to be run and in what order.
Rolling Back Changes
Early in my career (so about 12 years ago), I learned that whenever we wanted to release a change to the database, we had to provide to the DBA not only the script to make the change, but a script to undo the change. The script to undo the change was used by the DBA to undo any changes our script would make if there were any issues with the deployment.
This script was called a "rollback script". Most teams I have worked with have used rollback scripts during their deployments.
These rollback scripts are used to restore the database to the way it was before the deployment.
But what's the real purpose of these scripts?
It's to improve system stability. To reduce the time that a system is impacted by a faulty change. To prevent bugs and lost or corrupt data.
If you've ever written a script to perform a change to a database, you might know how hard it can be to write a script to undo it. It's not as easy as getting a previous version of code from source control.
Let's say you had a script that split a column into two, which was made by the following changes:
- Add two new columns to a table
- Populate data in these two columns from another column in a table
- Add an index to one of the columns
- Remove the initial column
You had tested the table structure with the new columns and it works.
But what about the rollback script?
The Problem with Rollback Scripts
To undo your changes you are often asked to write a rollback script. I believe that rollback scripts are unhelpful and should be avoided by implementing a better database deployment process.
Here's why I believe this.
Rollback scripts need to be tested. The scripts themselves need to be tested to ensure that they actually rollback correctly. You often need to restore data from other places and alter columns and tables. It's not as easy as just writing the script - you need to make sure it works if it is to be used to prevent possible database issues.
Rollback scripts add unnecessary overhead. Writing a script to deploy your database change is not enough. You need to write the rollback script, test it, document it, add it to version control, and provide it to the DBAs to deploy in case they need it. All of this is extra unnecessary overhead that the team can avoid.
Rollback scripts can be complex to write. Writing a rollback script isn't as easy as reversing the actions you took. You may need to restore data from other places or construct it using other fields. Tables may need to be recreated.
Using the earlier example, a rollback script would need to combine the two columns back into one using the same logic that was used to split them, maybe change data types, remove the index, remove columns, and test the result.
The Solution to Using Database Rollback Scripts
So what's the solution to rollback scripts? You can't just tell management that you're no longer going to be providing a way to recover from issues with deployments.
The solution is to write scripts that fix the problem. Write a patch or a roll-forward script.
You follow the same deployment process as a normal change. Ideally it will be automated (or automated as much as possible). Rather than writing a script that is run to reverse the changes, you write a script that fixes the issue that the changes brought in.
This script will go through your testing stages and deployment to other environments.
Did your script update a WHERE clause but not the related index, which caused a query to run a lot slower? Don't reverse your changes. Add a new deployment script to update the index.
Did your script add a new column with the wrong data type, or a length that was too short? Write a new script to change the data type or increase the length and deploy it.
The benefit of writing scripts to fix problems is that they follow the deployment process you have set up. They are tested (either automatically or manually), they go into version control, they are added to the version tracking table your tool has set up.
The effort you spend on developing a rollback script and process would be better spent on improving your database testing and deployment process to ensure issues are reduced in the future.
Bob Walker has also written a good article on rollback scripts with automated deployment.
Guidelines for Working With Database Deployments
If you want to follow a robust and automated database deployment process, there are some guidelines that you should follow. These are not firm rules, more like "highly recommended advice". They are gathered from my own experience and others who have implemented these.
Once a script is in source control, it cannot be changed.
A script is added to version control and is used by your system and tool to make a change to the database. If you want to make a change to the database, no matter how small, write a new script. Don't change an older script. K. Scott Allen writes more about this concept here.
Store both the schema and ref data in source control.
The database is made up of the schema (create and alter tables, views, sequences, other database objects) and any reference data (lookup tables). Scripts for both of these should be stored in source control so they can be used to rebuild the database in the future.
Apply all changes using scripts not manual changes.
It can be tempting to just log on to a QA or pre-prod to apply a fix to a database that you may have missed.
Avoid doing this. All changes should be done using the same process: writing a new script file and getting your deployment process to pick it up. This helps to avoid rogue changes in your database and to ensure consistency.
Ensure each developer has their own local database, not a shared development database.
In the earlier days of software development, creating a database was hard and time consuming. It was also expensive, taking up valuable space and memory on a server. So, developers had to have a shared development database.
Now, these problems are non-existent. Databases are easy to create and servers are more powerful. If you're a developer, ensure you and your team each have their own local development database. This allows you to make changes that don't impact anyone else until you commit your code. K Scott Allen has included this as one of his rules in his article Three Rules for Database Work.
Consider storing a hash of your database scripts.
If you adhere to the suggestion of not changing your scripts once they are run in your deployment process, it makes things easier.
However, sometimes people can forget and just make a change to an old script. This can cause problems for other team members or in other environments.
To avoid this, you can generate a hash value from your script file and store this in your database. When the file is changed, a new hash is generated which is then different from the old hash, and if it is different you can prevent the script from running. This can help reduce issues found in the deployment process.
Avoid exclusive locks in your scripts.
The scripts you write might either automatically or manually place exclusive locks on the tables they are working on. Try to avoid doing this in your deployment scripts, as this can slow down the deployment process. If there is a way to write your scripts to avoid this, then try to do so.
This depends on which database vendor you're using though, as some databases have table-level locks in some situations and others don't.
How to Implement This
So you've learned quite a lot in this guide on database version control and automated database deployment.
How do you implement this in your company or your team?
Firstly, it can take quite a while to get this implemented. The technical side can take some time (setting up the tools and the process). The personal side can also take time (convincing people that it's a good idea and building trust in the process).
Here's a high-level list of steps you can take to go from a manual database deployment process to an automated one.
- Consider using a small group of people to start, whether it's just yourself or a couple of others in the team as well.
- Generate a baseline schema for your database. This can be done manually (writing an SQL script) or generating it using your IDE (such as SQL Server Management Studio).
- Add your database script to source control.
- Decide on a tool to use for database changes and migration. Flyway was used as an example earlier, but the next section lists a whole range of tools you can use.
- Implement the chosen tool to handle your version-controlled scripts.
- Implement a local database for each developer (if you don't have one already)
- Update your deployment process (or create one) to generate the database from the scripts in source control
- Update the deployment process to deploy the scripts to your next environment (e.g. QA)
- Implement automated database tests. This can be a big step and something that is added to over time, and I'll cover this in another guide.
- Update the deployment process to deploy to your next environment (e.g. preprod)
- Update the deployment process to allow users to trigger a deployment to production when they want (and when the tests pass)
- Update the deployment process to automatically deploy to production.
There are a lot of steps in each of these, such as adding more tests and working with other teams to allow this, but this is the high-level process you may choose to follow.
Database Version Control Tools
There are many tools you can use to implement an automated database deployment process in your team and organisation. Here's a list you can choose from.
Flyway

Free
Website: https://flywaydb.org/
A popular free tool for database migrations and version control by Redgate. Your migration scripts can be written in SQL so there is no need to write in a separate language.
Liquibase

Free
Website: http://www.liquibase.org/
A free database migration tool that can have scripts written in SQL, JSON, YAML, or XML. A paid version is also available.
DBGeni

Free
Website: http://dbgeni.appsintheopen.com/
DBGeni helps to manage database migrations for several different database vendors.
Sqitch

Free
Website: https://sqitch.org/
Sqitch is a database change management framework and helps with database deployments.
Fluent Migrator

Free
Website: https://github.com/fluentmigrator/fluentmigrator
Fluent Migrator is a migration framework for .Net, similar to Ruby Migrations. It's available on GitHub.
DbUp

Free
Website: https://dbup.github.io/
DbUp is a .NET library that helps you to deploy changes to SQL Server databases. It tracks which SQL scripts have been run already, and runs the change scripts that are needed to get your database up to date.
SchemaZen
Free
Website: https://github.com/sethreno/schemazen
This is a tool that lets you script and create SQL Server objects easily.
DatabaseUpgradeTool
Free
Website: https://github.com/vkhorikov/DatabaseUpgradeTool
This is a light-weight tool for keeping track of your SQL database schema version.
Datical

Paid
Website: https://www.datical.com/
Datical is a paid tool for database release management and deployment. I've seen it mentioned in a few places.
DBForge Source Control

Paid
Website: https://www.devart.com/dbforge/sql/source-control/
This is a plugin for SQL Server Management Studio to allow version control of database code and objects. It supports many different version control systems.
SQL Change Automation

Paid
Website: https://www.red-gate.com/products/sql-development/sql-change-automation/
Redgate's SQL Change Automation is a tool to help you build, test, and deploy SQL Server databases.
SQL Source Control

Paid
Website: https://www.red-gate.com/products/sql-development/sql-source-control/
Redgate's SQL Source Control allows you version control your database schemas and data. It also includes a range of other features for database development.
Octopus Deploy

Paid
Website: https://octopus.com/
Octopus Deploy is a tool for managing database releases and automating deployments.
Delphix

Paid
Website: https://www.delphix.com/
Delphix is a tool for managing data that can do database deployments, but there is much more that it can do as well.
DBMaestro

Paid
DBMaestro is a tool that handles source code management and deployment for databases.
Apex SQL Source Control

Paid
Website: https://www.apexsql.com/sql-tools-source-control.aspx
This tool allows you to integrate source control with SQL Server Management Studio.
Servantt

Paid
Website: https://servantt.com/
Servantt is a tool for that makes it easy to reverse-engineer your database objects, compare database to the scripts, update the scripts or apply the changes to the SQL server.
Write your own tool
An alternative to using these tools is to write your own tool. You can tailor it to your own team's or organisation's requirements, but it may take you longer than using an existing tool.
Continuous Integration and Deployment Tools
You will also need a tool to perform an automated deployment of your application and database based on the code in your database. This is much more than a source control management or command line tool.
Some of the more popular ones are listed here. I won't go into too much detail in this guide, but consider looking into these tools and using one for your deployment process.
Jenkins

Free
Website: https://jenkins.io/
Jenkins is an open-source build automation server that can run CI and CD processes.
Bamboo

Paid
Website: https://www.atlassian.com/software/bamboo
Bamboo is developed by Atlassian, the team behind Jira and Confluence. It's a CI/CD tool for building and releasing software.
Azure DevOps

Paid
Website: https://azure.microsoft.com/en-us/services/devops/
Azure DevOps is a Microsoft tool for many things, including CI/CD. It was renamed from Visual Studio Team Services.
Travis CI

Free and paid
Website: https://travis-ci.com/plans
Travis is a CI service that you can use to build your applications.
TeamCity
Paid
Website: https://www.jetbrains.com/teamcity/
JetBrains, the company behind many IDEs and other development tools, have created TeamCity for CI/CD processes.
CircleCI

Paid
Website: https://circleci.com/
CircleCI is another CI/CD service that allows you to build, test, and deploy your applications.
How to Get Buy In
Getting the technical solution setup for database deployments is one thing. Getting agreement from others in the organisation can be harder. Here are some tips for getting other people on board with these changes.
Start small.
Use your own team as a starting point for automated database deployment. Don't try to get it all done and perfect the first time. We need to be patient when trying to improve the way things work. I have a habit of trying to rush things, but starting small and slow is a good way to get others to see how things work and to build trust in what you're doing.
Convince your team using manual work reduction.
If you want to convince your team that this is a good thing to do, let them know that with an automated deployment process, they will spend less time doing the manual steps for deployment. They will spend less time fixing bugs, and less time with the overhead (emails, approvals, meetings) to get releases done.
Convince DBAs using quality and time savings.
The DBAs may be the hardest group to convince, depending on your organisations. They have typically been the ones in control of the production database and often like to be able to sign off or approve the changes before they are made.
A good way to convince DBAs that this deployment process is a good one is to focus on the quality. Let them know that over time the quality of the process will improve due to automation and automated testing.
In the future there will also be less of a requirement on their time. They won't need to analyse, approve, and run scripts anymore, as this will all be automated. They can spend their time improving the database performance and other DBA tasks.
Convince management using time savings and reduced defects.
The way to convince management of the new database deployment process is to focus on two things: time (and cost) savings, and reduced defects.
Time savings are gained from the developers not having to spend time on release scripts and performing releases. Calculate the number of hours, and therefore money, that this process can save.
For example, each environment release may take an hour of a developer's time. Let's say you run three deployments per week (mostly to QA but some to preprod), which is three hours a week. Over a year (of 50 weeks, maybe excluding holidays), that's 150 hours.
Let's say the developers also spend two hours each production release, which happens every two months. So that's an extra 12 hours, with a total of 162 hours. If you use an average hourly rate of say $100, that's $16,200 per year in deployment work.
This effort can be eliminated if the process is automated. This is not just a cost saving, it's a time saving as well. The developers can spend their time on other tasks like fixing issues and delivering more value to the company. Using a tool, even a paid tool, will bring cost and time benefits.
With an automated release process, the organisation can also deploy more frequently, which improves the time to get value from their software.
Reduced defects come from an increased frequency of deployments (more smaller deployments = less risk of issues), automated testing, and less manual work. This can improve the reputation of the company, reduce the impact to customers and users, and improve the trust in the team.
Getting the OK from other people can take work, but the effort is worth it as the benefits of an automated deployment process are clear.
Conclusion
Automated testing and deployment of database code can be a big improvement to development teams. In the past, deployments were done manually and carefully, but with improvements in tools and technology, this can be automated, leaving you and your team more time to solve problems and work on interesting things.