A Guide to SQL NULL (and SQL NOT NULL)
The concept of NULL is something you should know about when working with databases.
In this article, you'll learn all about NULL: what it is, why it's different, how you can check for it in different databases, and many examples.

What Is NULL?
A NULL is how missing or unknown values are represented in many programming languages and databases. It represents "an unknown value".
When you want to store a value in a database column, you can add the value to the INSERT or UPDATE statement, and the value is stored.
But what if you, or the application that adds the data, don't know what the value is?
Some examples of this could be:
- A person not having a middle name
- A user not specifying an optional field on a sign-up form
- A user's profile picture, which is not specified initially but is updated later
In this situation, you could add a value such as "n/a" or 0 or "None".
But you may not have control of the query or logic that populates the fields.
Whether you can update the fields or not, you'll likely see NULL values in your data. You'll find out how to handle them in this article.
What Does a NULL Value Look Like?
A NULL value is usually shown as the word NULL in a result of a query. How it displays depends on your IDE.
Here's an example of how NULL values display in MySQL Workbench. This table is a list of superheroes that I prepared as part of the Superhero Sample Data post.
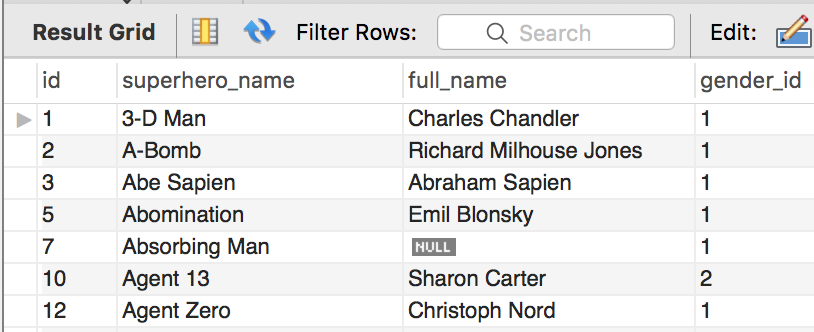
You can see in the image that there is a NULL value in the full_name column. This indicates that the full_name is not known for this record.
In other IDEs, this may show as (NULL) or (null) or
How to Check for NULL Values
When you want to write SQL to find a specific value, or to filter your results for a specific value, you use the WHERE clause.
For example, if you had a table of customers and wanted to find those that had a last_name of Smith, you could use this query:
1SELECT
2first_name, last_name, email_address
3FROM customer
4WHERE last_name = 'Smith';
The results could look something like this:
| FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|
| Sarah | Smith | ssmith@aol.com |
| John | Smith | johnsmith29@abc.com |
| Adam | Smith | (null) |
This shows records that have a last_name equal to Smith.
However, when filtering for NULL values, it works a little differently.
To find all records that are missing an email address, you might try this query:
1SELECT
2first_name, last_name, email_address
3FROM customer
4WHERE email_address = NULL;
If you run this query, you would not get any results.
Why is that? There is clearly at least one record with a NULL email address.
A column's value can be NULL, but it cannot be equal to NULL.
This may seem like a minor difference in words, but there is a big difference.
NULL is not equal to anything. It's an unknown value so there is no way to say that it is equal to any other value.
How can we check for NULL values then?
We use IS NULL. This is a keyword that lets you check if something is NULL. It works in a similar way to the = sign for other values.
Our query can be rewritten to look like this:
1SELECT
2first_name, last_name, email_address
3FROM customer
4WHERE email_address IS NULL;
Notice the only difference is the = NULL being changed to IS NULL.
The results could look like this:
| FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|
| Adam | Smith | (null) |
| John | Cooper | (null) |
It shows two rows that have a NULL email address.
So, this is how you check for NULL values. You use the IS NULL keyword.
How to Check for Values That Aren't NULL
When you write a query to check for columns values that aren't equal to something, you can use the not equal operator: either != or <>.
When working with NULL values though, you can't use these, as NULL cannot be equal to anything as mentioned earlier.
To check for values that are not NULL, you can use the keyword IS NOT NULL.
For example, to find customers that have an email address:
1SELECT
2first_name, last_name, email_address
3FROM customer
4WHERE email_address IS NOT NULL;
This query excludes customers where the email_address is NULL.
The results could be:
| FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|
| Sarah | Smith | ssmith@aol.com |
| John | Smith | johnsmith29@abc.com |
| Mary | Fisher | mf2000@abc.com |
We can see that the records we had in the previous query with NULL email addresses are not shown here.
So, to check for values that aren't NULL we use IS NOT NULL.
NULL with IN and EXISTS
There are two similar operators in SQL that let you check for a range of values: IN and EXISTS.
The IN keyword can use a set of values or a subquery. EXISTS is used with a subquery.
Both of these keywords can have the NOT keyword used with them: NOT IN and NOT EXISTS.
How does this relate to NULL values?
If you use a subquery inside either a NOT IN or NOT EXISTS clause, then a NULL value can show different results.
For example, let's say you had a list of emails, and you wanted to see which of them were not already in your list of customers. You could use NOT IN or NOT EXISTS for this.
The email_list table is shown below:
| EMAIL_ADDRESS |
|---|
| js1999@abc.com |
| sales@test.com |
| mf2000@abc.com |
| ssmith@aol.com |
The customer table is shown below:
| FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|
| Sarah | Smith | ssmith@aol.com |
| John | Smith | johnsmith29@abc.com |
| Adam | Smith | NULL |
| John | Cooper | NULL |
| Mary | Fisher | mf2000@abc.com |
To find the email addresses in the email_list table that aren't in the customer table using NOT EXISTS, this is the query:
1SELECT
2e.email_address
3FROM email_list e
4WHERE NOT EXISTS (
5 SELECT 1
6 FROM customer c
7 WHERE c.email_address = e.email_address
8);
The results are:
| EMAIL_ADDRESS |
|---|
| js1999@abc.com |
| sales@test.com |
To find the results using NOT IN, this is the query:
1SELECT
2e.email_address
3FROM email_list e
4WHERE e.email_address NOT IN (
5 SELECT c.email_address
6 FROM customer c
7);
The results are:
1No results found.
Why does NOT EXISTS return the correct result, but NOT IN returns nothing?
It's because of the way NOT IN works with NULL values. If any values found by NOT IN are NULL, the entire subquery returns NULL and therefore no results are shown.
So, if there is any chance that your subquery would return a NULL value, then avoid using NOT IN and use NOT EXISTS instead.
ORDER BY with NULL
Ordering your data with NULL values can cause some unintended results if you're not aware of how they are treated.
By default, when sorting data with NULL, these NULL values are:
- Shown at the beginning in MySQL and SQL Server
- Shown at the end in Oracle, PostgreSQL
For example, in MySQL:
1SELECT
2first_name, last_name, email_address
3FROM customer
4ORDER BY email_address;
| FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|
| Adam | Smith | (null) |
| John | Cooper | (null) |
| John | Smith | johnsmith29@abc.com |
| Mary | Fisher | mf2000@abc.com |
| Sarah | Smith | ssmith@aol.com |
The two rows with NULL are shown at the top of the result, then the email addresses are ordered by J, M, then S.
If you would prefer to have the NULL values at the bottom, you can order in descending order:
1SELECT
2first_name, last_name, email_address
3FROM customer
4ORDER BY email_address DESC;
| FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|
| Sarah | Smith | ssmith@aol.com |
| Mary | Fisher | mf2000@abc.com |
| John | Smith | johnsmith29@abc.com |
| Adam | Smith | (null) |
| John | Cooper | (null) |
But what if you want to order your values in ascending order and have the NULL values at the bottom? Or order in descending order with NULL values at the top?
You can do that in a few different ways.
The first way is by specifying either NULLS FIRST (show NULL values at the top) or NULLS LAST (show NULL values at the bottom). This only works in PostgreSQL and Oracle
Using NULLS FIRST:
1SELECT
2first_name, last_name, email_address
3FROM customer
4ORDER BY email_address NULLS FIRST;
Using NULLS LAST:
1SELECT
2first_name, last_name, email_address
3FROM customer
4ORDER BY email_address NULLS LAST;
The NULLS FIRST and NULLS LAST keywords are specifically designed to determine where NULL values should appear in the results.
Another way to order rows with NULL values is by using an expression. This can be done in any SQL version, but more often done in MySQL and SQL Server as they don't offer NULLS FIRST/NULLS LAST.
Using an expression:
1SELECT
2first_name, last_name, email_address
3FROM customer
4ORDER BY (email_address IS NULL);
Having the expression in brackets will return 1 if the email_address is NULL and 0 if it is not. This means the NULL values will be sorted last, which can be reversed by specifying DESC.
Column Defaults with NULL
When you create a new table, you specify columns and data types. When you INSERT data into the table, you specify the columns that you want to insert and the values for those columns.
Here's how we could create a customer table:
1CREATE TABLE customer (
2 id INT(11) PRIMARY KEY,
3 first_name VARCHAR(100),
4 last_name VARCHAR(100),
5 email_address VARCHAR(350)
6);
When you insert a new record, you need to specify a value for all columns that cannot be NULL. In this example, the id column is a primary key and therefore cannot be NULL. All other columns can be omitted.
An example INSERT query could be:
1INSERT INTO customer (id) VALUES (1);
This would work, and result in the following record:
| ID | FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|---|
| 1 | (null) | (null) | (null) |
The fields not specified have been given a value of NULL. When you write an INSERT statement and omit columns, a value of NULL is inserted for that record.
If you don't want to use NULL, you can specify the column value when you insert the record:
1INSERT INTO customer (id, first_name) VALUES (2, 'Jack');
| ID | FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|---|
| 2 | Jack | (null) | (null) |
The first_name has the value we specified, but the other columns are still NULL.
If you don't want to, or are unable to, specify the values during the INSERT, you can set the default values when you create the table.
You add the word DEFAULT after the column definition, then specify the value:
1CREATE TABLE customer (
2 id INT(11) PRIMARY KEY,
3 first_name VARCHAR(100),
4 last_name VARCHAR(100),
5 email_address VARCHAR(350) DEFAULT 'None'
6);
The email_address field in this example has had DEFAULT 'None' added to the definition. This means that when an INSERT statement runs and a value is not specified for this column, the value of "None" is used.
1INSERT INTO customer (id, first_name) VALUES (3, 'Susan');
| ID | FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|---|
| 3 | Susan | (null) | None |
The id and first_name values are specified. The last_name is not specified so a NULL value is used. The email_address field is not specified, but the default value of "None" is used.
NOT NULL Constraints
As we saw earlier, you can specify NULL values for columns, or omit them from your INSERT statements to store a NULL value in a column.
But what if you don't want to store NULL values in a column? What if you want to prevent NULLs from being added?
You can do this in the database using a NOT NULL constraint.
A NOT NULL constraint is a type of constraint that prevents NULL values from being added to a column.
To add one, you simply add the words NOT NULL after the column definition.
For example, to ensure that the email_address cannot be NULL:
1CREATE TABLE customer (
2 id INT(11) PRIMARY KEY,
3 first_name VARCHAR(100),
4 last_name VARCHAR(100),
5 email_address VARCHAR(350) NOT NULL
6);
This means you can still INSERT values for the email_address, but you can't INSERT a NULL value.
So this statement will work:
1INSERT INTO customer (id, first_name, email_address) VALUES (4, 'Jane', 'jane@test.com');
| ID | FIRST_NAME | LAST_NAME | EMAIL_ADDRESS |
|---|---|---|---|
| 4 | Jane | (null) | jane@test.com |
But this statement shows an error:
1INSERT INTO customer (id, first_name) VALUES (5, 'Stephen');
Depending on your database vendor (Oracle, MySQL, etc), you'll get an error similar to this:
1ORA-01400: cannot insert NULL into ("CUSTOMER"."EMAIL_ADDRESS")
2ORA-06512: at "SYS.DBMS_SQL", line 1721
So, using a NOT NULL constraint is a good way to ensure that data is captured in a field and not just left as NULL.
Handling NULL Values
NULL values behave differently as we've seen in this article so far.
Sometimes, when you're working with data, you don't want to see NULL values in a SELECT statement or insert them in an INSERT statement.
There are a few functions in each type of database that you can use to handle NULL values.
CASE
All database vendors support the CASE statement, and this can be used to handle NULL values.
For example:
1SELECT
2CASE
3 WHEN email_address IS NULL THEN 'Not specified'
4 ELSE email_address
5END AS email_address
6FROM customer;
The CASE statement is quite powerful and can be used to change NULL values in your result set to something else.
COALESCE
The COALESCE function is part of the SQL standard and included in many database vendors. It returns the first non-NULL value it finds in the supplied parameters.
1COALESCE (expression1, expression2, expression3…..)
For example:
1SELECT
2COALESCE(personal_email, work_email, alternative_email)
3FROM customer;
This query would return personal_email, but if that is NULL it would return work_email, and if that is NULL then alternative_email is returned.
NULL Functions in Oracle
The functions in Oracle to handle NULL values are NVL and NVL2.
1NVL (expression1, expression2)
The NVL function will check expression1. If expression1 is not NULL, it is returned. If expression1 is NULL, then expression2 is returned. It's like a simple IF statement.
1NVL2 (expression1, expression2, expression3)
The NVL2 function will check expression1. If expression1 is NOT NULL, then expression2 is returned. If expression1 is NULL, then expression3 is returned. It's a function with a bit more flexibility than NVL.
NULL Functions in SQL Server
The ISNULL function in SQL Server will check if a value is NULL.
1ISNULL (expression1, expression2)
If expression1 is not NULL, it is returned. If expression1 is NULL, then expression2 is returned. It's like a simple IF statement and similar to the Oracle NVL function.
NULL Functions in MySQL
MySQL has a function called IFNULL.
1IFNULL (expression1, expression2)
If expression1 is not NULL, it is returned. If expression1 is NULL, then expression2 is returned. It's very similar to SQL Server's ISNULL and Oracle's NVL functions.
NULL Functions in PostgreSQL
There are no specific functions for handling NULL values in PostgreSQL. However, you can just use either COALESCE or CASE as mentioned above.
Conclusion
NULL values represent an unknown value and are often found in SQL statements and table columns. They behave differently to other values and you need to be aware of some differences, especially when working with NOT IN and NOT EXISTS.
Many databases used in production have NULL values, and the better you understand how these values work, then the easier your life will be.